Post-Request/Response Apps
Serverless or monolithic/'serverful' architectures are often presented as sides of the same coin: they're both just alternative ways to serve synchronous requests, for example, a HTTP server serving content, or handling API requests publicly or internally.
But this is a naïve viewpoint, and we as developers now almost see 'serverless-like' development as the silver bullet for potentially enormous scalability, throwing away the imperative nature of writing long-lived server code. We've collectively forgotten how to write servers!
(Remember that serverless is broadly defined as computing which scales easily, but with no reliable state—every request may be handled by a new process, which is orthogonal to a long-lived server.)
Of course, it's fairly easy to list the pros and cons of serverless vs monolith through the lens of synchronous requests only: many articles do. But this doesn't consider an application, system, whatever you're doing, holistically—you're focusing only on the pointy end, how your components interact.
This article will talk through why serverless adds needless complexity, and provide actual concrete examples of how, where and why to adopt monolithic—importantly, horizontally scalable monolithic—approaches to backend design. Read on. 🥳
Background on Serverless vs Other Approaches
Again, serverless is computing that scales easily, with the tradeoff that it's stateless. (And it can be great for work that's actually stateless!)
We see fairly broad implementations of serverless:
- you have Cloudflare Workers, which pushes your code right to the edge, and has amazing performance properties
- AWS Lambda is the original, but it really embodies the above definition: yes, it scales, but it's slow to start up and each instance only handles one request at once (which is painful when you're probably further I/O bound within the Lambda)
- Google's Cloud Functions is a nice middle ground, as its v2 supports concurrency
All of these can be wired up to serving user requests, webhooks, callbacks, whatever (the world is HTTP, after all). It's also worth honing in on what 'stateless' actually means—every request handled by your serverless code may be in a fresh VM. (Although in reality, most providers reuse VMs for a short time, or this is configurable—restarting is costly for them too.)
On the other hand, we have non-serverless code, where a VM's lifetime is much longer (it won't live forever, but who does), and typically can serve many requests in parallel. Environments that run this code often (but not always) allow you to scale horizontally, allowing you to run a configurable number of instances which are used based on the requestor's geolocation, server load, even randomly, or perhaps with a session affinity cookie/header.
- AWS has Fargate, which is their solution for "just let me scale VMs please"
- fly.io provides these options, as it provides a single anycast address plus HTTPS certs for any service you run—doing intelligent routing and running code worldwide
- your suggestion here?
Thesis
My thesis is that serverless' biggest trade-off is it being stateless. Because running code this way is intentionally unreliable, serverless requires you to express your state externally: at best in a database, and at worse as the machniations of a complex system with queues, events and state offloaded to your cloud provider's… "primitives".
We, as software engineers, already have a great way to hold state: in memory.
And the advent of serverless has encouraged us to think of all possible serving options as analogies to serverless, where their only job is to serve requests as fast as possible with the existential dread that the process may be evicted at any point.
We, as backend developers, have collectively forgotten how to write code that considers the current process' interaction with a client to be a long-term arrangement. And, to be fair, this isn't guaranteed either, short of using a monolith (that is, O(1) server, rather than O(n)) servers): the internet is a hectic place, and two HTTP requests made by the same client might not be routed the same way.
The Alternative
So, Sam, you say that serverless is poor, but then disregard that point by telling me that we should either use an O(1) monolith or give up because HTTP requests will route oddly. What's your point?
Well, the point is that there's a number of patterns that blow serverless's complexity right up, and we should actively be seeking out imperative solutions (even if a bit tricky) rather than just adding more serverless: those "primitives" I mentioned earlier.
To quote a developer I mostly admire:
The solution to serverless always looks like more serverless.
…the meaning here being that serverless taints your thinking: it's always one more construct, rather than just being able to write imperative code.
And while that above explanation sounds good, it's still abstract. There's two main points you need to consider when architecting something that encapsulates long-term state.
-
What types of tasks are good candidates. This is the concrete 🏗️ example part—what are the goals with serverless that you keep thinking, if only I could bend over backwards even more…
-
How you can ensure that an end-user can access that state. This is subtle, but important, because of the HTTP request routing above. If a horizontal monolith is taking on some task, but a client (website, app, or even other service) no longer has affinity to that target (whatever reason), how do you 'join' again?
1. Serverless Sucks For
Medium-Running Tasks
Let's say you have a user-initiated batch task: something that you'd love to do a in single HTTP request from a client, but which takes just a bit too long, say a data conversion or an export task. And you're thinking—oh no, do I need to set up queues, event busses, more infrastructure just to do this thing? Think a few minutes' long, where you'd like to give user feedback.
Serverless tends to make this hard because:
- serverless functions tend to have hard execution limits (although they are going up these days)
- But they are modelled entirely as request/response beasts—yes, you could have the function emit status update logs you consume elsewhere, but fundamentally they're not designed to give intermediate feedback.
With long-running instances, we can have the ability to simply do work for a long period of time, disconnected from the request/response cycle. What a concept! 🤯
You might architect this through a task that subscribes to a database (used like a queue), enacts a lock on a task, and undertakes it. If the job dies, the lock expires and you pick up the task again.
Or you could start these tasks in direct response to a user's network request, and your frontend simply undertakes some CPU-bound work for a while before its result chills in memory for the user, or is pushed back via a socket.
Single-Homed Logic
Think of Google Docs as a good example. Each document has a unique ID and is fundamentally brought into memory and run somewhere when it is opened by any number of users. It exists in a database, yes, but a client 'joins' a single process which manages its OT logic.
In a serverless land… oh wow. This is almost untenable; you could do it by having each operation (a keystroke, pasting text) talk to any serverless function, open a shared database, and perform an atomic operation on that database. Simultaneously, the client is polling or fetching changes from that same database, so it can keep in sync with other clients.
This really rolls up two really tricky things for serverless:
- a place to run long-term imperative code over time without the risk of ☠️
- global locks, or a way to say "this instance is the host" of the document 🔒🎯
And the same idea could apply to more complex applications, for example, building a Slack or Discord-like service might have each 'server' run its logic imperatively on a unique machine.
🌈 Shameless Plug 🌈 This is one of the use-cases of locksrv, my offering that can provides fast yet global locking of unique IDs.
But also, you can use Cloudflare's Durable Objects for this purpose, too.
To be fair, this problem doesn't need global locks—each document ID could itself embed a home region (where most of its users are), and then a lookup to a fast key/value store like Dynamo could tell you who's currently the boss.
Agent Behavior
Not that kind of agent 🕴️.
I've danced around this point, but one of the approaches we've lost when building serverless is the idea that your interaction with a website, app, whatever, is actually both happening in the client and on the server. And instead of just connecting to a grabbag of lambda helpers, we could connect to a task, the agent, which is dedicated to helping us.
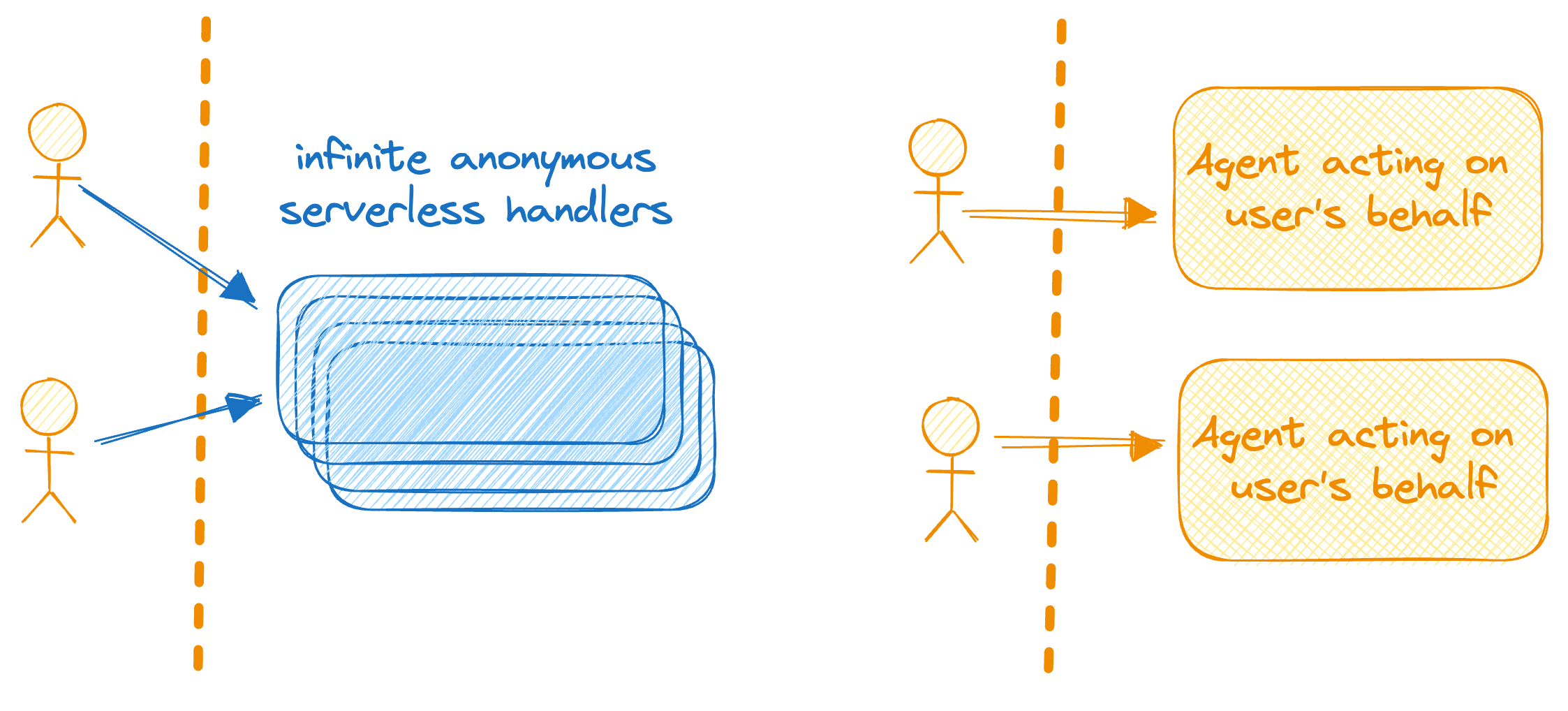
Now, an agent here might not map 1:1 to each e.g., open browser tab—maybe it's an agent per sign-in, so the same auth details get help from the same VM. Maybe it's an agent or pool of agents per company using your premium SaaS.
Why does an agent help you? It acts as your generalized bridge into a hosted part of any product, doing things on behalf of the user. Now, that's abstract, I confess, but…imagine a world where:
- you're using AWS, and you're recieving some update over SQS or an event bus
- these services don't have a client-facing version, i.e., they can't be directly wired to an end user
- it's totally possible to rig up serverless code to itself be called on an event, which puts something into a database, which a user polls, but…you see where I'm going here.
Instead, have an agent working on behalf of the user which when instructed, listens to SQS and identifies events for its client. It could even fall back to polling a database or checking logs if no answer arrives in time. It then pushes the update over a user's open socket, or stores it in local memory until the user is able to read the answer—if the user 'disconnects' for a minute, the agent stays awake and ready for a short timeout!
What about a simpler example? A user could make a complex SQL or SQL-like query, where the results are complex to compute. While a backend can quickly return a small number of responses, an agent could continue preparing more—with the assumption that another request will arrive soon after for additional results.
The point being here is that dances like this should be compartmentalized inside simple, imperative code rather than a million lines of config orchestrating ostensibly cheap 'on-demand' infrastructure. 🔥
2. Accessing That State; or, HTTP is ephemeral
However, back to my earlier issue: if HTTP requests route anywhere—isn't this just serverless all over again?—what's even the point of doing this work? 🤔🤔🤔
Again, this could be solved by an actual monolith, where you only have a single server. But that isn't the point of this post.
Socket
One way to guarantee that the user will get access to whatever imperative code is to actively pin the connection to a remote server, literally via a long-running connection: a WebSocket.
(In the future, this will include WebTransport, but it's not widely available yet.
You could also use Server-Sent Events, but this is only ½ of the solution.)
This punches a hole through any kind of odd routing or concern about affinity. Your client can directly connect to a server which might do work for you.
There's caveats: sockets are good for the 'agent' model, where you only have O(1) connection per-tab (or perhaps per service worker, but that's a whole other blog post). And while the point of this post is that you can have long-lived code with horizontal scaling, if you don't have enough load to be distributed evenly, then one server VM may end up randomly being assigned too many socket connections.
Pedants might note that AWS, for example, has a serverless WebSocket solution.
But it's fundamentally an antipattern: it removes all benefits of WebSocket, instead mapping it back to request/response.
It gives none of the benefits of a long-lived socket.
HTTP or request/response
We could attempt to emulate a socket-style experience in HTTP with pure hope—modern HTTP/2+ is designed to use the same 'connection' for many requests.
But we can't guarantee that, and imagine a network drop: even our reliable WebSocket can disconnect and need to retry.
There's a couple of approaches here, some of which I've already alluded to:
-
Most cloud providers allow for session affinity (via cookie, their front-ends will route you) or targeting specific VMs.
AWS has "sticky sessions", Google has affinity, Fly.io allows targeting a specific instance—any client in a relationship with a backend can retry its requests with this custom header. If one of your servers sees a request for its peer—redirect it that way!
-
Using serverless-style front-ends which themselves perform affinity routing to a further layer based on your own code. This can be fairly stateless, and less 'obvious' to evil actors—the affinity token might be encrypted or actually be a lookup to a global lock service (again, 🌈 let me know if I can help 🌈).
Best Effort
Finally, the 'agent' example above doesn't actually care that much about session affinity—or, at least, you can leverage it when it works (which, again, is often in the world of HTTP/2+) and just accept when it doesn't as a "cost of doing business".
Think of it like a boring old cache implemented in memory, but instead of purely caching some, e.g., database rows, you're actually 'caching' some running code on behalf of a user assuming that you'll see them again. And if you don't see them again, there's no harm, the code stops after a timeout; the client will retry and hit another process which starts the agent anew.
Discussion
What is Serverless good for? I want to be clear, this is not (entirely) a hit piece. But it should be used sparingly, for reasons like:
- glue code between other services which need to trigger a callback—this is literally the origin of it at AWS
- short CPU-bound work that can be surprisingly unexpected for your service—if you say, batch convert images for the public, maybe you can do it here
- as a stateless replacement for awkward configuration languages—e.g., Cloudflare/CloudFront Workers can set headers or wrap up tricky results
- small/underutilized services where running 24/7 might be costly—although platforms like Fly.io and Cloud Run can actually mitigate that, by giving you far more control over your VM's start and stop times.
I think the complexity of real servers (or VMs, whatever) can also be a lot for new developers. I get that. Firebase Functions (just wrapped Google Cloud Functions), for example, is pitched at a low/no-code world: you largely have a static site and just need to slowly add some dynamic logic. As long as your model fits in that request/response model, sure—but don't let the tool limit your thinking that even toy apps can't or don't need a long-lived component.
Finishing Up
I'll say it again: I've seen serverless being used because it's viewed as this 'silver bullet' for one day landing on the front page of Hacker News. And that it's "all people know these days"—just using React as a stack, which is almost just an attempt to make your job posting seem sexy at this point—so of course you'll mention the buzzword when hiring. (I would!)
So while serverless can have its place, it represents the unfortunate baseline that other approaches tend to be measured against in common discussion. And the reality is that it brings every other possible approach down to its level.
Cheers 👋
I run a course called Polaris for upcoming leaders and CTOs of tech startups in Sydney, Australia, where I have opinions like this. I'm also available for consulting if you'd like to pay me to rephrase the content in this post especially for your company. 💸