AWS Amplify Is A Grift
Yes, this is a punchy headline, but if you'll join me on this journey, you'll see how. 👀
So, here's the context. For the past year or so, I was at a renewable energy startup. It was a great experience, but I recently resigned: I'm having another child, and I just don't need to work full-time—so I'm not going to. To be clear, this post is entirely my opinion: as of writing, I'm only employed by myself.
The startup heavily used Amplify—I inherited that decision—but one of my major initatives was removing as much of it as possible. This took hundreds of engineering hours away from actual work.
So, let me be as clear as possible, and you can quote me personally on this: "AWS Amplify is actively harmful", primarily because of its database choice.
Consider using just a normal database—personally for me that would be Firestore (Google-hosted) or MongoDB (basically self-hotsed), because I strongly prefer scalable NoSQL databases. But for most people, it's probably going to literally just be Postgres. You don't need more than Postgres.
How can a framework be actively harmful?
A core idea of cloud providers is that you can build your infra and not have to worry about scale. AWS Amplify makes promises that it will be:
Easy to start, easy to scale
But herein lies the grift: it's useless for anything except toy applications with trivial amounts of data. And these toy apps are conveniently easy to demo.
And data is the key here; there's a lot of AWS Amplify which is just fine and boring, like its user authentication libraries. The issue lies with GraphQL and the way it stores data.
The challenge, of course, is that you don't know that it's terrible going in: that's why I'm writing this post. The issue is that it it's built by the world's biggest cloud provider, who is completely happy to pay US$200k/yrs to DevRels to push this unusable bit of software—so you might think, sure, it's fine.
But it's not. 💥
The Boring Stuff
Let's get the boring stuff out of the way. By that, I mean the parts of AWS Amplify that are innocuous, indifferent, and are plainly things that are hard to mess up or be particularly amazing at.
-
Cognito: Amplify sets up an auth stack. It's got its own problems (including poor SSO integration that actively leaks all configured integrations), but if all you want is basic email/password login, it's fine. I've heard on the grapevine that Amplify's client-side JS is actually the best way to interact with Cognito.
-
Hosting: There's a YAML-based config language which sets up some basic CI/CD to deploy your website. It's fine.
-
Analytics: It's broken. If the same user signs in on a large number of different browsers (you'd never do that while debugging, in multiple Incognito windows—never!) then you generate too many IDs for that user and events can no longer be logged.
-
Some AI stuff: I haven't used this. It seems like it's just AWS wrapping up its more complex services with… exactly the same level of complexity, but now it has a 🌈 brand 🌈.
Again, this is fine. Any provider pitched at the same level—Firebase, Supabase, Azure probably has one—has this kind of "app-builder" stack.
Data, It's What Apps Crave
AWS Amplify allows you to specify GraphQL models that turn into database rows. To be fair, this is an annoying problem: let's say you're DIYing it, and writing a GraphQL server and database integration yourself.
- If you're using a traditional SQL database you'll have to write both the GraphQL schema and the table schema.
- If you're using NoSQL, you may have to massage your GraphQL types before storing them—since GraphQL's type system is needlessly restrictive.
However, the fundamental mistake that's made here is that AWS Amplify puts your data into DynamoDB, which is not a general-purpose database.
Amplify's approach in using DynamoDB is literally called out as something you should avoid by AWS, because it uses a single table per resource. Additionally, you cannot filter or sort by arbitrary columns—DynamoDB is a high-performance, low-level database, that doesn't let you do arbitrary queries. That's the point.
Yes, Amplify awkwardly describes the way you can create secondary indexes, but it's often not what you need (everything needs primary AND secondary keys, etc), and you can't index on any sort of ACLs.
So using it is literally an anti-pattern. And part of the problem is, once you're in production using a database—whatever database, not just DynamoDB—it's hard to get out.
But DynamoDB Scales?
But Sam, you say—DynamoDB is a fast, scalable database. Surely these tradeoffs are worth it?
Yes, in some cases. But you should only use it when a traditional database won't cut it (and if you think you know what that threshold is, go and double the number and come back to me), and you can confidently design your queries up-front.
Amplify, which is literally pitched at startups, isn't suitable because you're going to pivot. Your CEO is going to ask you for some weird data 'shape' that just isn't possible because Dynamo plainly cannot answer your arbitrary queries. Yes, no data is ever in a perfect table, but this makes it worse.
There is a flipside, which is that Dynamo is fairly fast at a "scan", which is a fancy term for "load every row and filter it at runtime". And yes, if you don't have much data—again, think of a number and add an order of magnitude to it—you can just do that, but then why are you using DynamoDB? Dynamo scales by sharding—your primary key space is divided ito partitions. But a partition is literally 10gb of data.
- If you're storing that much plain text data, good for you—maybe DynamoDB can help you!
- If you've only hit 10gb since you're putting large binary data into your database, you should rethink your choices.
So if your company doesn't have that much data (even 100gb might be a good target), but chooses to use Dynamo, your effective option to do arbitrary queries is just to… scan all the data.
So why are you using Dynamo, a hyper-performant and extremely limited database, again? 🤔
But DynamoDB Is Fast?
Ah, well, here's the real killer.
If you put access controls on your data, and say, a user wants to retrieve their "Foos"… AWS Amplify literally has to fetch matching data and then filter it down.
Let me say that again.
If you have 1,000 users, and each privately owns one row of data, Amplify's default pagination of 100 items per fetch will take—in the worst case—O(users/100) pages to retrieve the user's item.
For 1,000, that's 10 pages.
For 100,000, that's 100 pages—100 round trips from your user's web browser back to the database.
The VTL, a language used by AppSync, which is Amplify's underlying provider, looks like the following (a tiny bit snipped for brevity).
And note that the 'data source' items are in $ctx.result.items—that's the page we have to scan to see if a user can see their own data.
#set( $items = [] )
#foreach( $item in $ctx.result.items )
## [Start] Dynamic Group Authorization Checks **
#set( $isLocalDynamicGroupAuthorized = false )
## Authorization rule: { allow: groups, groupsField: "groupsWithRead", groupClaim: "cognito:groups" } **
#set( $allowedGroups = $util.defaultIfNull($item.groupsWithRead, []) )
#set( $userGroups = $util.defaultIfNull($ctx.identity.claims.get("cognito:groups"), []) )
#foreach( $userGroup in $userGroups )
#if( $allowedGroups.contains($userGroup) )
#set( $isLocalDynamicGroupAuthorized = true )
#end
#end
## [End] Dynamic Group Authorization Checks **
#if( ($isLocalDynamicGroupAuthorized == true) )
$util.qr($items.add($item))
#end
#end
#set( $ctx.result.items = $items )
Yes. It's really that bad. Of course, Amazon's sample resolvers (not that you write VTL directly with AWS Amplify) don't include this—they have a single line saying, "oh, you'll just pass all the data back to the client".
What Else Is Wrong?
The above criticism, the run-time filtering of user data, is by far the most egregious failure of AWS Amplify. There's a number of other poor areas, too.
Firstly, GraphQL subscriptions are basically useless. There's a great blog post here which covers this far better than I can.
And Amplify's DataStore fails fundamentally because it relies on GraphQL subscriptions and Amplify's view on that. It doesn't support dynamic ACLs (which is technically listed in the docs but not at all clear), so you can only listen to public items, which is bizzare. And it falls into the traps above. There are so many issues about how it's unusable and how the people filing didn't realize until they were already knee-deep in Amplify's grift.
Additionally, the JS used by AWS Amplify allows for race conditions in listening to changes. What do you do when you want a list of "live" objects? You'd imagine something like:
- You request the complete list of objects
- You listen for changes to those objects
And that's what Amplify does, … but here's the kicker, in a diagram:
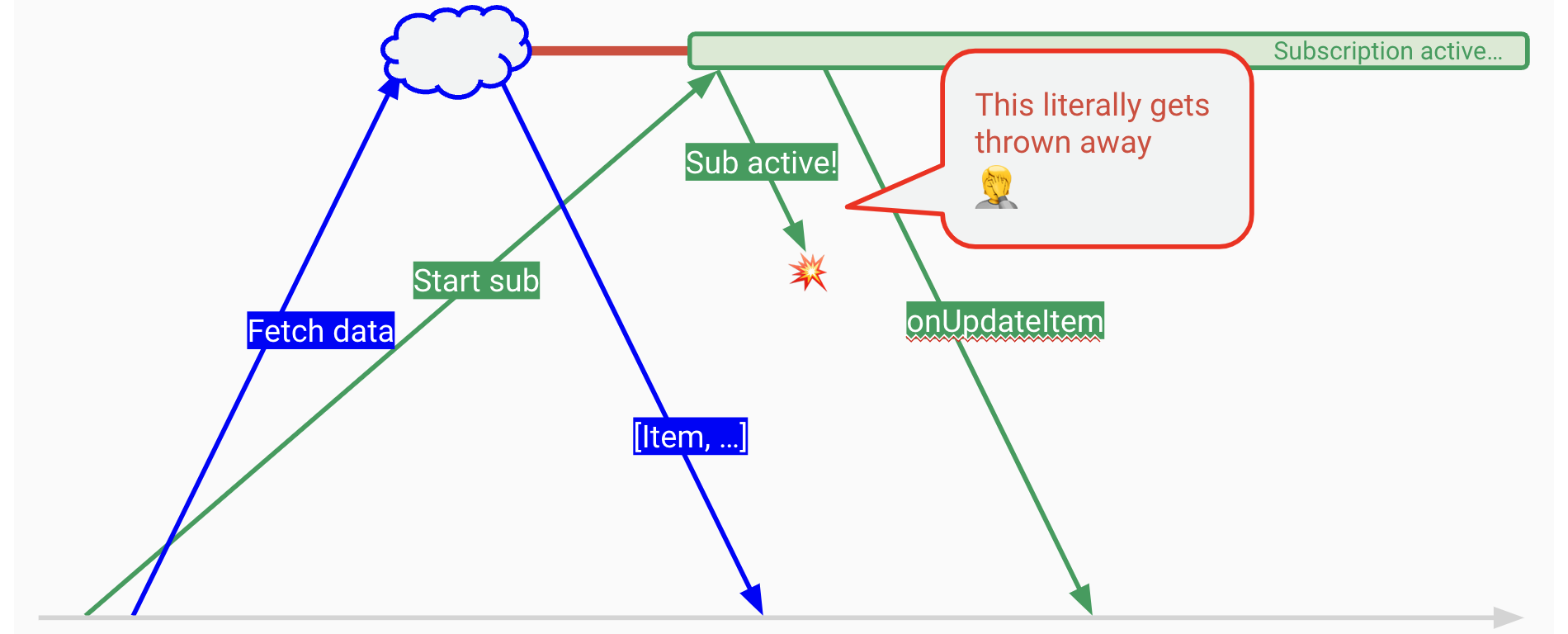
So you're going to risk losing changes. And for most users—sure, that's fine. What are the odds of something happening in that red area? But it's poor design.
I know there's a slightly tweaked approach that has revision numbers and so on, but it's not commonly understood.
I cannot stress how much Google's Firestore just solves the 'real-time' problem. Instead, for days and days, I've had to work around Amplify's limitations.
What Should AWS Do?
So, you say: Sam, you've complained a lot. But Amplify has some redeeming characteristics. How could you make it better?
If I was AWS, I would…
- provide Postgres or similar as a database choice: This allows a developer's database schemas to include fairly arbitrary indexes (because you're not limited by DynamoDB)
- incorporate ACLs into that database's indexes: ACL-ed queries are 'slow' because they take the dumbest approach
- rebuild subscriptions without GraphQL: Implement a log-based solution which lets users catch up on a single table they're interested in, but trade off "nested" queries (it's not GraphQL anymore)
- rethink whether GraphQL is actually fit for purpose: It's just not very good, aside from nested queries. That's a whole different post, though.
What Should You Do?
If you're already commited to AWS Amplify, then I'm sorry. The auth and non-database world—that's fine. I even enjoy or think that the JWT-based approach to auth is actually fairly good, and you can write alternative backends which use a user's claims to enforce ACLs.
I think the thing I'd do is… if you're somewhat "successfully" using Amplify right now, I believe that your model and data won't actually be that large—because it actually breaks down at big numbers. Therefore it is the right time to rethink.
Look at your queries which are particularly awkward—what does your app or company have the most of? Can that be refactored into its own system, potentially wrapping up a database that's more fit for purpose?
Remember too that most applications will have a notion of login, user, settings—fairly boring stuff. If that's in Amplify, fine. A lot of it is probably ID-based, which Dynamo actually does excel at—you're not listing every user to get to your own. So that can remain.
Thanks For Reading
This space isn't perfect, but I honestly believe Amplify has too many potholes to justify its use, and those are wrapped up in poor documentation that hides a lot of nuances that aren't obvious when you start and only hit you when you're actually trying to scale.
Best of luck. 😬
Find me on Bluesky. I'm also available for consulting.
An Addendum
Update, April 2023: This post ended up on the front page of HN. I'd like to call out some themes in the comments:
-
AWS uses Dynamo as it has no other Serverless database offering: This is actually a fairly astute observation. Amplify is pitched as a serverless product, and I'm not sure what AWS has in the database space that doesn't "run all the time"—running Postgres or Mongo would cost you ¢/hour.
-
You shouldn't be using Dynamo for your data model: Sure, that's why this post exists. As a developer using a new app builder platform, it's not clear where the minefields are, and AWS Amplify doesn't make it clear from the outset that it has these really hard limitations around ACLs, speed etc. AWS isn't going to come out and say "Our database is a bit shit, but the rest of Amplify is perfectly cromulent.".
-
Postgres vs NoSQL: I don't see Firestore (NoSQL) or Postgres being that different. I like Firestore. I think it's the world's best general-purpose database. But Postgres is similar enough, I think it just comes down to personal preference. DynamoDB, on the other hand, … is not really either of those things to me. It's a lower-level construct that people often build real general-purpose databases with, but which is highly limited on its own. This is my thesis: Amplify is doing the tech space a misservice by using DynamoDB.