Node.js Streams & Object Mode
Streams in Node.js serve two purposes.
The first, more commonly documented use-case is that of reading and processing bytes a 'chunk' at a time: bytes which most commonly come to/from your local disk, or are being transferred over a network.
Secondly, you have {objectMode: true}, which I'll explain later.
tl;dr: Streams for bytes are rarely useful, and objectMode can be made better through parallelism (which most libraries don't take advantage of).
Chunks of Data
The classic use of stream works with files or file-like objects directly. For example, you might read, compress and write out a file, which looks a bit like:
import fs from 'fs';
import {createGzip} from 'zlib';
const src = fs.createReadStream('image.tar');
const transform = createGzip();
const dest = createWriteStream('image.tar.gz');
// now connect! \o/
src.pipe(transform).pipe(dest);
Without streams, you'd have to read the whole file at once rather than processing it in, well, a stream of smaller chunks. So, you basically want this for one of two reasons:
- a file is enormous so loading it all into memory at once is wasteful
- or; your task involves a network in any way (so you can send or use bytes immediately)
Interacting with the network is a natural fit for streams, because the network is slow. You don't want to block until a whole file is a in memory, and only then send it over a relatively slow connection to your users.
However, when you're just processing files as part of a script, streams are rarely useful. Tasks like compression make great examples, as their algorithms just don't need the whole file at once. But anything outside this definition doesn't work this way—think compiling source files, resizing images—in places where the full context is required, streams don't make sense.
To look at a popular build tool, Gulp, only one of its top ten popular plugins supports streaming mode (gulp-replace).
As an aside, Gulp is an interesting example, because a lack of support in any given plugin will always throw an error—it's actively hostile to streams.
Speed Comparison
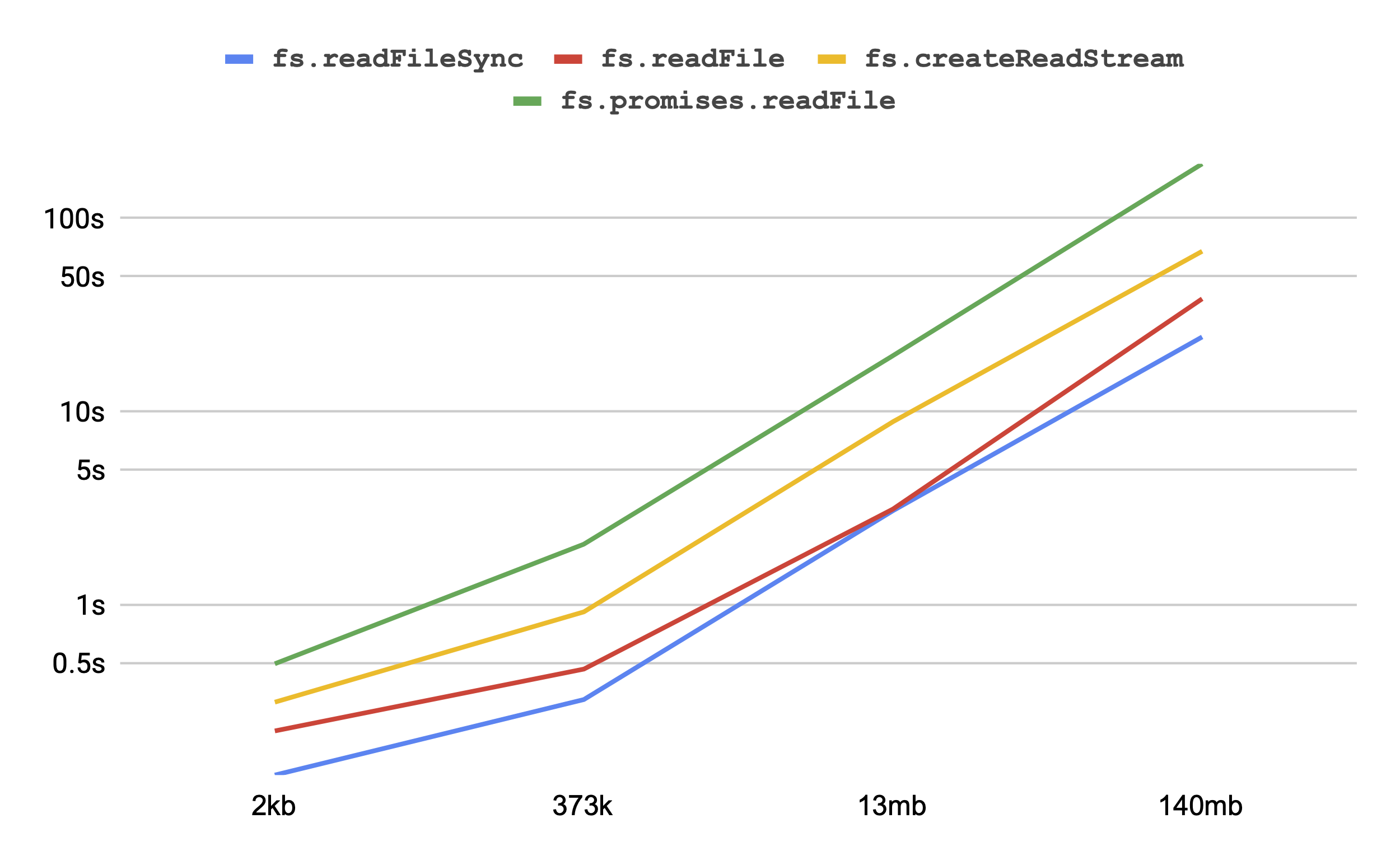
fs.readFileSync is much faster than streaming dataIf your goal is to just read a whole file into memory as quickly as possible, fs.readFileSync is the champion, with fs.readFile (the callback-based version) slightly behind.
Building the most simple of streams—just getting every chunk and putting it into an array—is about 2-3x slower.
Interestingly enough, is that using fs.promises.readFile is about 2-3x slower again.
If you're worried about performance, maybe avoid it for now (Node v13).
Object Mode
Where streams come into their own, however, is when they're used in {objectMode: true}.
Instead of transferring 'chunks' of a file, you can use them to move literally any object.
Let's start with an example—again using Gulp.
Gulp is described as a "streaming build system", but 'streaming' here refers specifically to the Vinyl file objects it generates—which are passed through plugins with objectMode.
Gulp's tasks look a bit like this:
gulp.task('images', () => {
return gulp.src('images/*.{png,gif,jpg}')
.pipe(imagemin())
.pipe(gulp.dest('dist/images/'));
});
The first call, gulp.src, starts a stream that reads files matching a certain glob.
It then pipes the stream to a transform which modifies each file (in this case, minifies them) before finally to a writer that puts them on your disk again.
This is a powerful primitive, but it has some serious caveats. Some of them seem like poor design choices in Node which would be impossible to change after so many years.
Caveats
Streams, and the way they pipe together, aren't useful for constructing some permanent structure or scaffold.
In the following example, we generate helper streams that emit some numbers.
Once the first Readable is complete it will call the .end() method of the thing you've piped through to.
Have a read:
import stream from 'stream';
import * as transforms from 'async-transforms';
const doSomething = transforms.map((each) => console.info(each + 1));
stream.Readable.from([1, 2, 3]).pipe(doSomething);
setTimeout(() => {
// the setTimeout shows that the above Readable
// is closing the stream after a frame
stream.Readable.from([4, 5, 6]).pipe(doSomething); // won't run, won't crash
}, 0);
The program will only output "2, 3, 4" (the values passed in the first stream).
To be fair, we can fix this behavior by passing {end: false} as an option to the .pipe call—but this is something the user of a stream decides on, not the author.
To put it another way, if you're writing a library that exposes a stream target, any part of a program that uses your stream can cause you to stop receiving input. This is a challenging place for library authors to be in.
Streams also historically don't do anything sensible with errors.
The .pipe() command doesn't forward errors—check out a bunch of other posts about why this is bad.
The modern solution to errors, and which also makes streams a bit nicer to write code for, is the stream.pipeline static method.
This was added in Node v10, seemingly as a concession that the previous model hasn't worked that well.
Paralellism in Object Mode
One of the great reasons to use objectMode streams is part of a build process or similar pipeline.
The reason I've used Gulp as an example is that it pioneered this approach.
However, not every implementer of a transform or other parts of a stream gets parallelism right. This is the relevant line from Node.js' docs:
transform._transform()is never called in parallel; streams implement a queue mechanism, and to receive the next chunk, callback must be called, either synchronously or asynchronously.
If you were to implement a transform as the docs suggest:
const t = new stream.Transform({
transform(object, encoding, callback) {
doComplexTask(object, (result, err) => {
callback(err, result);
});
}
});
... then only a single chunk will be processed at once. This probably makes sense for chunked binary data, but rarely for objects. Let me explain.
If you're writing a transform that compiles SASS or resizes a number of images on-disk, and each object is a filename or file contents, then it's unlikely that the order of the output matters, or that each task is related in any way.
So, naïvely, you can run all your tasks in parallel by:
const t = new stream.Transform({
transform(object, encoding, callback) {
callback(); // "done" already, send me more please
doComplexTask(object, (result, err) => {
err ? this.emit('error', err) : this.push(result);
});
}
});
The tradeoffs of this simple design are basically:
- tasks will complete in any order
- you'll run all the tasks as fast as they arrive—maybe they shouldn't all run at once, even for CPU or memory-related reasons
(The second point actually doesn't matter too much in Node.js, as it's single-threaded: at most, you could burn through one of your CPUs, unless your "complex task" is actually spawning another thread.)
Async Transforms Library
Yes, this post is mostly advertising for a library I've written. The async-transforms package has a number of stream helpers which implicitly work in parallel, and allow you control the number of tasks to use.
import * as transforms from 'async-transforms';
const compileTransform = transforms.map(async (file) => {
const {code} = await expensiveCompileTask();
return code;
}, {tasks: 4});
It's also got a number of other helpers, including farming work out to a Worker inside Node.js (so CPU-bound tasks can run on their own thread).
I'll let you take a read of its documentation, but it works around both tradeoffs of the naïve design, above.
As a fun aside, one of the most egregiously poor bits of JavaScript advice I've seen on the internet is that forEach and map on your stock-standard Array type work in parallel.
Nothing could be further from the truth—these are clearly defined to work step-by-step.
Proper use of streams, however, can get you close to that vision.
Summary
Streams are confusing. You probably don't need them for reading or writing bytes, unless you have a niche use-case (including interacting with the network).
Streams in objectMode have more utility, but know that they're not a silver bullet to all types of program flow, and that most folks implementing transforms build them in a completely serial way.